Employee Portal AI Chat App
Introduction
The AI Chat app, which I developed, was designed as a feature for the employee portal dashboard. This was during the early stages of AI chat adoption, aimed at enhancing productivity in the workplace. Existing solutions at that time were deficient in reporting capabilities and lacked the necessary security measures for widespread AI deployment in organizations. They also fell short in providing management with cost estimates and censorship tools essential for maintaining information security. With these gaps in mind, I designed the AI Chat app to offer auditability of usage, cost transparency, and proactive security measures. These measures include filtering out sensitive information leveraging the capabilities of Local LLMs.
Features
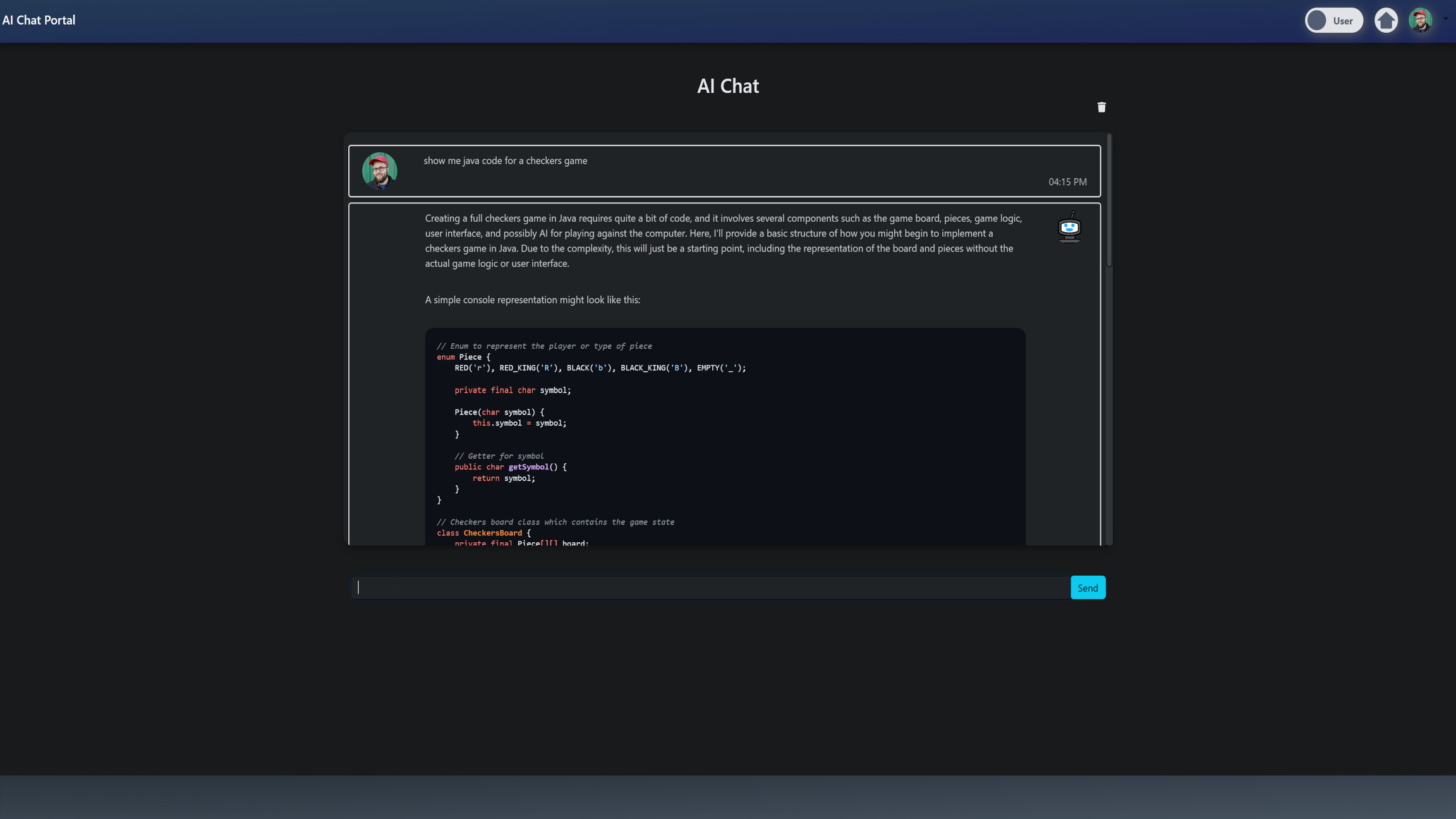
Chat With Chat GPT
The selected code snippets are written in Python and are part of a Django web application that makes up the Chat AI app. They are designed to facilitate a chat interface between a user and an AI model, specifically OpenAI's GPT model. The code is organized into three main functions: home(request), ajax_chat(request), and chat_with_gpt(user_instance, user_input).
The home(request) function is a Django view function that handles the home page of the AI chat. It uses the @login_required decorator, which is a feature of Django's authentication system that ensures only authenticated users can access this view. If a user is not authenticated, they are redirected to the login page.
The function first checks if the user has an associated AIChatUserSetting object and if the enabled attribute of this object is True. This is done using Django's ORM (Object-Relational Mapping) system, which allows for database queries to be written in Python. If the user does not have an AIChatUserSetting object or if enabled is False, the user is redirected to the home page of the core application, which is the Employee Portal main dashboard.
If the request method is POST, the function is designed to handle post data, although the specifics of this handling are not provided in the selected code. If the request method is GET, the function retrieves the user's messages from the Message model, sanitizes them using the bleach library to prevent XSS (Cross-Site Scripting) attacks, converts them to markdown format using the markdown library, and sends them to the aichat_index.html template to be displayed.
@login_required
def home(request):
# Check if user has AIChatUserSetting and if enabled is True
try:
user_settings = AIChatUserSetting.objects.get(user_ID=request.user)
if not user_settings.enabled:
return redirect("core:home")
except AIChatUserSetting.DoesNotExist:
return redirect("core:home")
if request.method == "POST":
# Handle your post data here
pass
else:
processed_messages = Message.objects.filter(
user=request.user, archived=False
).order_by("timestamp")
raw_messages = Message.objects.filter(
user=request.user, archived=False
).order_by("timestamp")
# Convert markdown messages to HTML with bleach sanitization
for processed_message in processed_messages:
# First, clean the message using bleach
cleaned_message = bleach.clean(processed_message.message, strip=True)
# Adding the raw message attribute and storing a text only version of the message
setattr(processed_message, "raw_message", cleaned_message)
# Now, convert the cleaned message to markdown
processed_message.message = markdown.markdown(
cleaned_message, extensions=extensions
)
context = {
"processed_messages": processed_messages,
}
return render(request, "user/aichat_index.html", context)
ajax_chat(request) function is another Django view function that handles AJAX requests for the chat. It performs similar checks as the home(request) function to ensure the user has the necessary permissions to use the chat. If the request method is POST, it validates the form data using Django's form system, sanitizes the user input, processes the input through the chat_with_gpt(request.user, cleaned_input) function, sanitizes the AI response, and returns the response in JSON format using Django's JsonResponse class. If the form is invalid, it returns an error response.
@login_required
def ajax_chat(request):
# Check if user has AIChatUserSetting and if enabled is True
try:
user_settings = AIChatUserSetting.objects.get(user_ID=request.user)
if not user_settings.enabled:
raise PermissionDenied("You are not permitted to use this chat.")
except AIChatUserSetting.DoesNotExist:
raise PermissionDenied(
"You do not have the necessary permissions to use this chat."
)
if request.method == "POST":
form = ChatForm(request.POST)
if form.is_valid():
user_input = form.cleaned_data["textareafield"]
# Sanitize the input with bleach
cleaned_input = bleach.clean(user_input, strip=True)
# Process the sanitized input (AI chat logic, etc.)
ai_response = chat_with_gpt(request.user, cleaned_input)
# Sanitize the AI response as well
cleaned_ai_response = bleach.clean(ai_response, strip=True)
# Adding the raw message a text only version of the message
ai_raw_response = cleaned_ai_response
# Convert markdown messages to HTML
rendered_ai_response = markdown.markdown(
cleaned_ai_response, extensions=extensions
)
return JsonResponse(
{
"ai_response": rendered_ai_response,
"ai_raw_response": ai_raw_response,
}
)
else:
# handle invalid form, e.g. return an error response
error_response = (
"Error: Please provide valid input for me to help you with."
)
rendered_error_response = markdown.markdown(
bleach.clean(error_response, strip=True), extensions=extensions
)
return JsonResponse({"ai_response": rendered_error_response})
The chat_with_gpt(user_instance, user_input) function handles the interaction with the GPT model. It first checks if the user input is not empty. Then it retrieves the user's AIChatUserSetting and applies various redactions based on the user's settings. This is done to protect sensitive information such as names, addresses, credit card numbers, bank information, API keys, and social security numbers.
The function then checks if the token count of the user input is within the user's maximum limit and if the rate limit is not exceeded. This is done to prevent excessive usage of the GPT model, which can be costly. If all checks pass, it sends the user input to the GPT model and stores the user input and AI response in the Message model. It also updates the Usage model with the total tokens used and the total requests made. If any of the checks fail, it returns an appropriate error message. If an exception occurs, it returns a generic error message.
def chat_with_gpt(user_instance, user_input):
total_tokens_used = 0 # Initialize before the block
response = None # Initialize before the block
ai_response = ""
if not user_input.strip():
return "Error: Please Provide Some Input For Me To Help You With."
try:
user_settings = AIChatUserSetting.objects.get(user_ID=user_instance)
ai_model = user_settings.model_ID
# Filter input if it is required
if user_settings.redact_name:
user_input = redact_names_efficient(user_input)
if user_settings.redact_address:
user_input = redact_addresses(user_input)
if user_settings.redact_credit_card:
user_input = redact_credit_cards(user_input)
if user_settings.redact_bank_info:
user_input = redact_bank_info(user_input)
if user_settings.redact_api_key:
user_input = redact_api_keys(user_input)
if user_settings.redact_ssn:
user_input = redact_ssn(user_input)
# print(user_input) commented out for testing
encoding = tiktoken.get_encoding("cl100k_base")
token_count = len(encoding.encode(user_input))
if (
token_count <= user_settings.request_token_maximum
and token_count != 0
and check_rate_limit(user_instance, ai_model)
):
openai.api_key = ai_model.api_key
messagesRequest = [{"role": "user", "content": user_input}]
if user_settings.context:
previous_messages = Message.objects.filter(user=user_instance).order_by(
"-timestamp"
)[: user_settings.context_previous_count]
for msg in previous_messages:
role = "assistant" if msg.type else "user"
messagesRequest.insert(0, {"role": role, "content": msg.message})
response = openai.ChatCompletion.create(
model=ai_model.name,
messages=messagesRequest,
max_tokens=user_settings.response_token_maximum,
)
ai_response = response.choices[0].message["content"]
total_tokens_used = response["usage"]["total_tokens"] # Update the value
Message.objects.create(
user=user_instance,
model=ai_model,
token_total=response["usage"]["prompt_tokens"],
type=False, # User Request
message=user_input,
)
Message.objects.create(
user=user_instance,
model=ai_model,
token_total=response["usage"]["completion_tokens"],
type=True, # AI Reply
message=ai_response,
)
if response: # Add this condition
today = date.today()
usage_records = Usage.objects.filter(
user=user_instance,
model=ai_model,
period_start__year=today.year,
period_start__month=today.month,
)
if usage_records.exists():
usage_record = usage_records.first()
usage_record.running_token_total += total_tokens_used
usage_record.running_request_total += 1
usage_record.save()
else:
Usage.objects.create(
user=user_instance,
model=ai_model,
period_start=today,
running_token_total=total_tokens_used,
running_request_total=1,
)
else:
if not check_rate_limit(user_instance, ai_model):
ai_response = f"Error: You've Hit Your Limit Of {user_settings.requests_per_rate} Messages Per {user_settings.rate_duration} Please Wait."
elif token_count == 0:
ai_response = "Error: Please Provide Input For Me To Help You With."
else:
ai_response = "Error: Please Shorten Your Message Length. You've Hit Your Message Length Limit."
return ai_response
except AIChatUserSetting.DoesNotExist:
return "Error: User Does Not Have Associated AI Chat Settings."
except Exception as e:
# return f"Error: {str(e)}"
return f"Error: OOPs ... Something Went Wrong"
Limit Usage
I also wrote a function to implement rate limiting for users interacting with an AI model. Rate limiting is essential to ensure fair usage and prevent any single user from monopolizing the system's resources.
The function checks how many requests a user has made to a specific AI model within a defined time period (like an hour, day, week, or month). It retrieves the user's rate limit settings, calculates the relevant time window, and counts the number of requests made in that period. If the user has not exceeded their allowed number of requests, the function returns True; otherwise, it returns False. This helps manage and control the usage of the AI model efficiently.
def check_rate_limit(user, model):
try:
user_settings = AIChatUserSetting.objects.get(user_ID=user, model_ID=model)
except AIChatUserSetting.DoesNotExist:
return False
rate_duration = user_settings.rate_duration
requests_per_rate = user_settings.requests_per_rate
current_time = timezone.now()
if rate_duration == AIChatUserSetting.HOUR:
start_time = current_time - timedelta(hours=1)
elif rate_duration == AIChatUserSetting.DAY:
start_time = current_time - timedelta(days=1)
elif rate_duration == AIChatUserSetting.WEEK:
start_time = current_time - timedelta(weeks=1)
elif rate_duration == AIChatUserSetting.MONTH:
start_time = current_time - timedelta(weeks=4)
else:
return False
message_count = Message.objects.filter(
user=user,
model=model,
timestamp__gte=start_time,
timestamp__lt=current_time,
type=False,
).count()
return message_count < requests_per_rate
So, the first thing this function does is try to fetch the user's settings for the specific model they're interacting with:
user_settings = AIChatUserSetting.objects.get(user_ID=user, model_ID=model)
If it can't find any settings (maybe because they don't exist), it catches that exception and returns False right away:
except AIChatUserSetting.DoesNotExist:
return False
Next, it grabs the rate_duration and requests_per_rate from those settings, and also records the current time:
rate_duration = user_settings.rate_duration
requests_per_rate = user_settings.requests_per_rate
current_time = timezone.now()
Now, based on the rate_duration, it calculates the start_time for the rate-limiting window. This part uses some straightforward if-elif conditions to figure out how far back in time we should start counting requests:
if rate_duration == AIChatUserSetting.HOUR:
start_time = current_time - timedelta(hours=1)
elif rate_duration == AIChatUserSetting.DAY:
start_time = current_time - timedelta(days=1)
elif rate_duration == AIChatUserSetting.WEEK:
start_time = current_time - timedelta(weeks=1)
elif rate_duration == AIChatUserSetting.MONTH:
start_time = current_time - timedelta(weeks=4)
else:
return False
With the start_time set, the function then counts the number of requests the user has made to the model within this window. It queries the Message table, filtering by the user, model, and the time range:
message_count = Message.objects.filter(
user=user,
model=model,
timestamp__gte=start_time,
timestamp__lt=current_time,
type=False,
).count()
Finally, it compares the count of these requests to the allowed number of requests per the user's settings. If the user hasn't exceeded their limit, it returns True; otherwise, it returns False:
return message_count < requests_per_rate
So, that's how the function works! It checks if the user is within their allowed request rate, ensuring they don't go over their limit.
Redact Sensitive Information
I also wrote functions to redact sensitive information such as names and addresses from text inputs. This is important for protecting privacy and ensuring that any shared or stored text does not inadvertently expose personal details.
The first function, redact_names_efficient, removes personal names from the input text using a Natural Language Processing (NLP) model:
def redact_names_efficient(text):
# Check for non string input
if not isinstance(text, str):
raise TypeError("Input must be a string")
# Process the text
doc = nlp(text)
# Initialize variables
redacted_text = []
last_index = 0
# Iterate over the detected entities
for ent in doc.ents:
if ent.label_ == "PERSON":
# Debug: Print the entity and its position
# print(f"Detected entity: '{ent.text}' at position {ent.start_char}-{ent.end_char}")
# Add text up to the entity
redacted_text.append(text[last_index : ent.start_char])
# Add redacted name
redacted_text.append("[Redacted Name]")
# Update the last index to the end of the entity
last_index = ent.end_char
# Add the remaining text after the last entity
redacted_text.append(text[last_index:])
return "".join(redacted_text)
First, the function checks if the input is a string:
if not isinstance(text, str):
raise TypeError("Input must be a string")
Next, it processes the text with an NLP model:
doc = nlp(text)
It then iterates over the detected entities in the text:
for ent in doc.ents:
if ent.label_ == "PERSON":
# Add text up to the entity
redacted_text.append(text[last_index : ent.start_char])
# Add redacted name
redacted_text.append("[Redacted Name]")
# Update the last index to the end of the entity
last_index = ent.end_char
Finally, it appends the remaining text after the last detected entity and returns the redacted text:
redacted_text.append(text[last_index:])
return "".join(redacted_text)
The second function, redact_addresses, redacts addresses from the input text:
def redact_addresses(text):
if not isinstance(text, str):
raise TypeError("Input must be a string")
doc = nlp(text)
redacted_text = []
last_index = 0
combined_matches = []
for ent in doc.ents:
if ent.label_ in ["GPE", "ORG", "LOC"]:
combined_matches.append((ent.start_char, ent.end_char))
# Updated regex pattern with case-insensitive flag
address_pattern = r"\b\d{1,5}\s\w+\s(Street|St|Avenue|Ave|Road|Rd|Boulevard|Blvd|Lane|Ln|Drive|Dr)\b"
for match in re.finditer(address_pattern, text, re.IGNORECASE):
combined_matches.append((match.start(), match.end()))
combined_matches.sort(key=lambda x: x[0])
for start, end in combined_matches:
if start >= last_index:
redacted_text.append(text[last_index:start])
redacted_text.append("[Redacted Address]")
last_index = end
redacted_text.append(text[last_index:])
return "".join(redacted_text)
Similar to the previous function, it starts by checking if the input is a string:
if not isinstance(text, str):
raise TypeError("Input must be a string")
It processes the text with an NLP model and initializes variables:
doc = nlp(text)
redacted_text = []
last_index = 0
combined_matches = []
It then detects geographical entities (like locations) and uses a regular expression to find address patterns:
for ent in doc.ents:
if ent.label_ in ["GPE", "ORG", "LOC"]:
combined_matches.append((ent.start_char, ent.end_char))
address_pattern = r"\b\d{1,5}\s\w+\s(Street|St|Avenue|Ave|Road|Rd|Boulevard|Blvd|Lane|Ln|Drive|Dr)\b"
for match in re.finditer(address_pattern, text, re.IGNORECASE):
combined_matches.append((match.start(), match.end()))
It sorts the matches and redacts the detected addresses:
combined_matches.sort(key=lambda x: x[0])
for start, end in combined_matches:
if start >= last_index:
redacted_text.append(text[last_index:start])
redacted_text.append("[Redacted Address]")
last_index = end
Finally, it appends the remaining text after the last detected address and returns the redacted text:
redacted_text.append(text[last_index:])
return "".join(redacted_text)
Both functions help ensure that any shared or stored text is free of sensitive personal information, thus maintaining privacy and security.
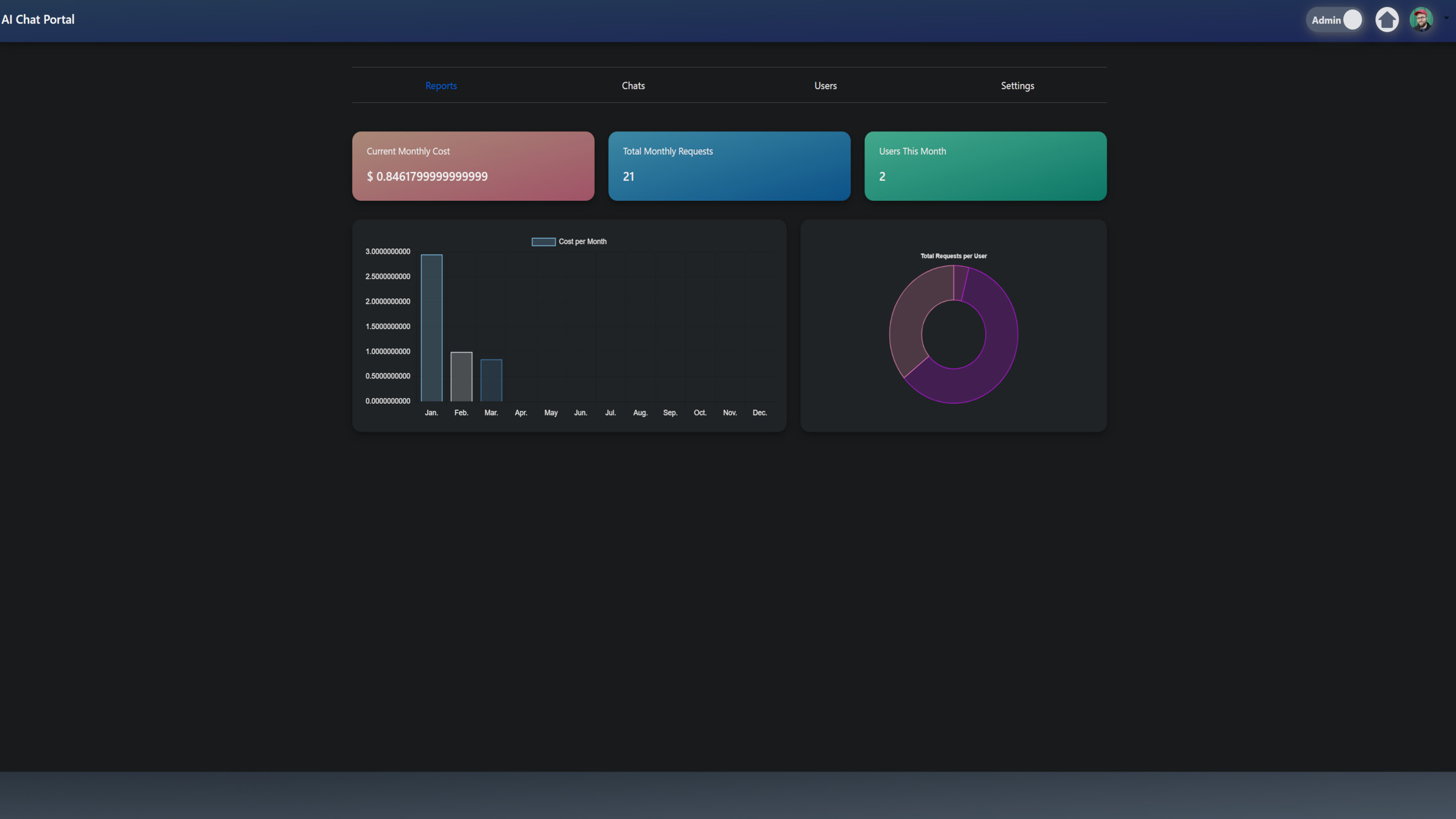
Admin Reports
I also developed a function to generate administrative reports for AI model usage. This function provides monthly statistics, including total costs, the number of requests, and the number of users interacting with the AI models. It helps administrators monitor and manage system usage and expenses.
Here’s the function to generate the admin reports:
@staff_member_required
def admin_home(request):
current_total_monthly_cost = 0.0
current_total_monthly_requests = 0
current_total_monthly_users = 0
monthly_costs = [] # To store the total cost for each month of the current year
# Get the current time in UTC
today = timezone.now()
for month in range(1, 13): # Iterate through each month (1 to 12)
# Define first_day_of_month here, within the loop
first_day_of_month = timezone.make_aware(datetime(today.year, month, 1))
# Define last_day_of_month here, within the same loop
if month == 12:
last_day_of_month = timezone.make_aware(
datetime(today.year + 1, 1, 1) - timedelta(seconds=1)
)
else:
last_day_of_month = timezone.make_aware(
datetime(today.year, month + 1, 1) - timedelta(seconds=1)
)
monthly_cost = 0.0 # Initialize monthly cost for the current month
# Assume AIModel and Message are defined models in your application
ai_models = AIModel.objects.all()
for ai_model in ai_models:
input_cost = 0.0
output_cost = 0.0
messages = Message.objects.filter(
model=ai_model,
timestamp__gte=first_day_of_month,
timestamp__lte=last_day_of_month,
)
for message in messages:
if message.type:
output_cost += (message.token_total / 1000) * float(
ai_model.output_cost_per_1k_tokens
)
else:
input_cost += (message.token_total / 1000) * float(
ai_model.input_cost_per_1k_tokens
)
monthly_cost += input_cost + output_cost
monthly_costs.append(monthly_cost) # Append the monthly cost to the array
# Calculate metrics for the current month
first_day_of_current_month = timezone.make_aware(
datetime(today.year, today.month, 1)
)
# Fix for handling December
if today.month == 12:
last_day_of_current_month = timezone.make_aware(
datetime(today.year, 12, 31, 23, 59, 59)
)
else:
next_month_start = timezone.make_aware(
datetime(today.year, today.month + 1, 1, 0, 0, 0)
)
last_day_of_current_month = next_month_start - timedelta(seconds=1)
current_total_monthly_cost = monthly_costs[today.month - 1]
current_total_monthly_requests = Message.objects.filter(
timestamp__gte=first_day_of_current_month,
timestamp__lte=last_day_of_current_month,
type=True,
).count()
current_total_monthly_users = (
Message.objects.filter(
timestamp__gte=first_day_of_current_month,
timestamp__lte=last_day_of_current_month,
type=True,
)
.values_list("user", flat=True)
.distinct()
.count()
)
users_with_message_count = CustomUser.objects.annotate(
message_count=Count("message", filter=Q(message__type=True))
)
usernames = [user.username for user in users_with_message_count]
message_counts = [user.message_count for user in users_with_message_count]
context = {
"current_total_monthly_cost": current_total_monthly_cost,
"current_total_monthly_requests": current_total_monthly_requests,
"current_total_monthly_users": current_total_monthly_users,
"monthly_costs": monthly_costs,
"usernames": usernames,
"message_counts": message_counts,
}
return render(request, "admin/aichat_admin_index.html", context)
Here’s a breakdown of what this function does:
-
Initial Setup: It starts by initializing variables to keep track of the current month's costs, requests, and users, as well as an array to store the monthly costs for the entire year.
-
Current Time: It gets the current time in UTC.
-
Monthly Iteration: It iterates through each month of the current year, calculating the first and last day of each month. This is done to gather and compute costs for each month.
-
Cost Calculation: For each month, it calculates the input and output costs by iterating through all AI models and their respective messages within the month. Input and output costs are computed based on token usage and the respective cost per 1k tokens.
-
Appending Costs: The computed monthly costs are appended to the
monthly_costsarray. -
Current Month Metrics: It calculates the metrics for the current month, including the total cost, the number of requests, and the number of unique users.
-
User Statistics: It gathers the usernames and their respective message counts.
-
Context Setup: It prepares the context with all the gathered data to be rendered in the admin template.
This function allows administrators to have a comprehensive view of the system’s usage, helping in making informed decisions and ensuring efficient resource management.
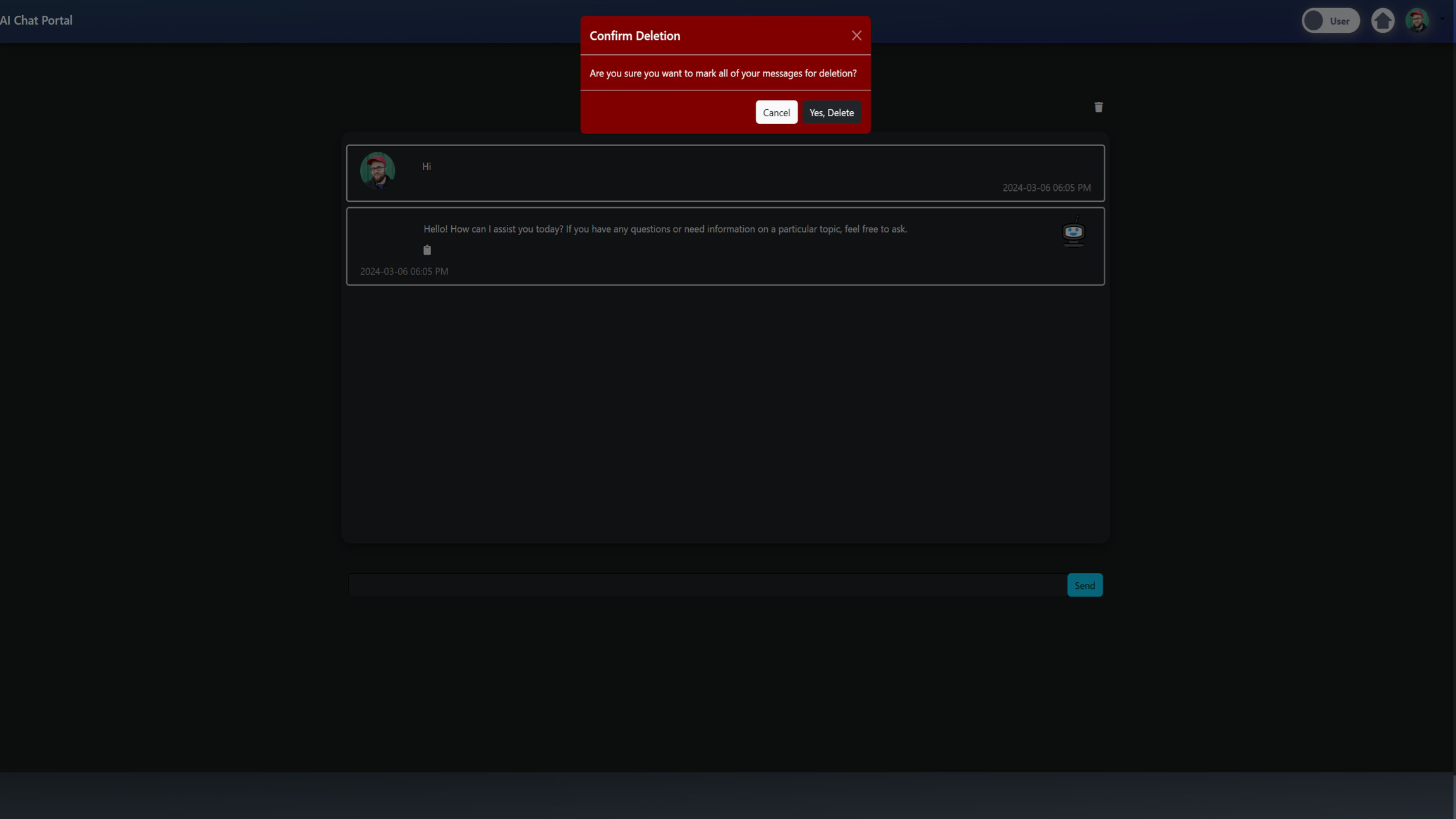
Admin Delete Chats
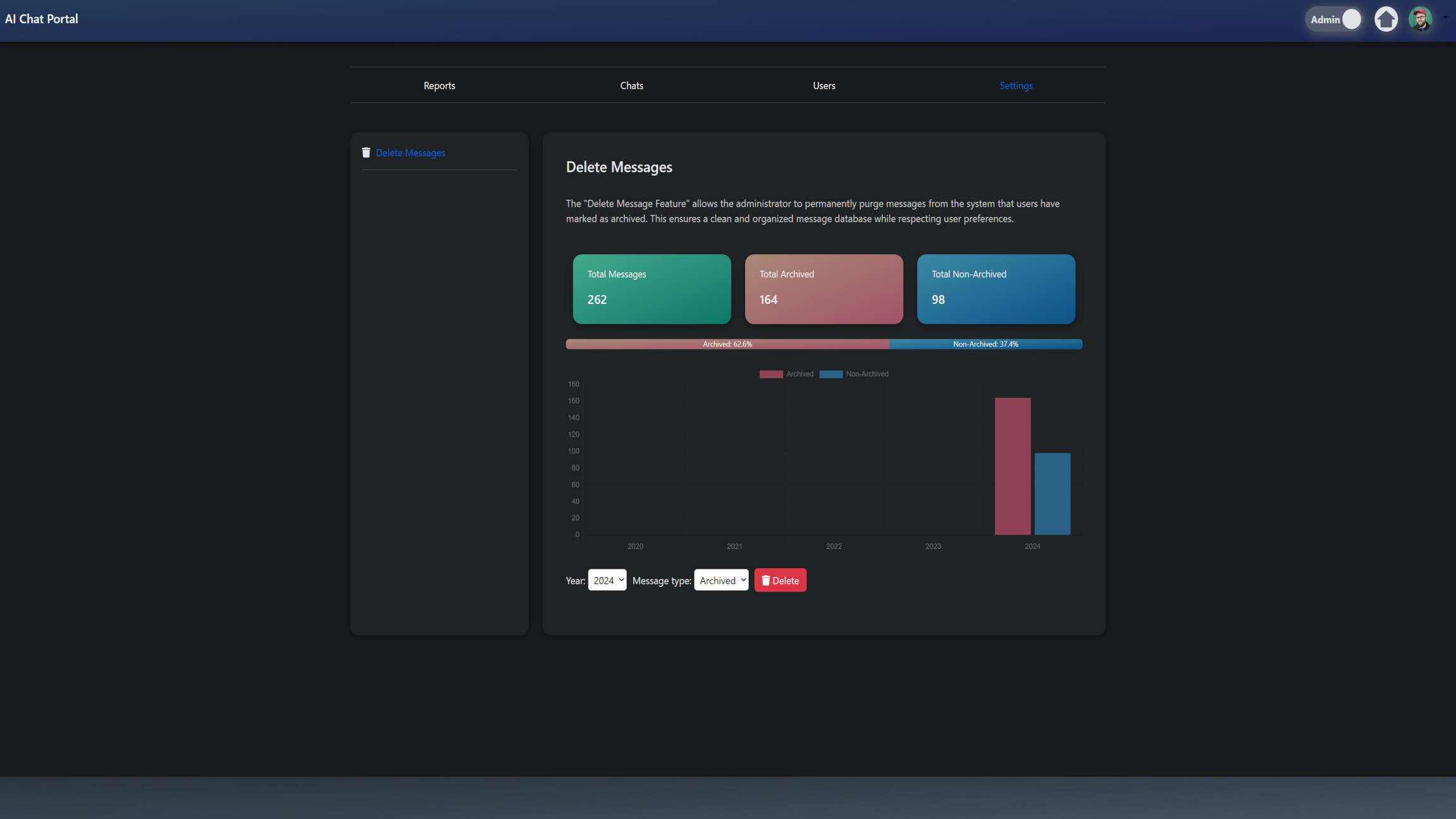
I also created a function to handle the deletion of messages in the admin settings. This feature allows administrators to manage and clean up chat data efficiently, providing insights into message counts and enabling the deletion of messages based on certain criteria.
Here's the function that implements this:
@staff_member_required
def admin_home_settings(request):
# Admin Message Delete - Progress Bar and Message Counts by Type
total_messages = Message.objects.count()
archived_messages = Message.objects.filter(archived=True).count()
unarchived_messages = total_messages - archived_messages
if total_messages != 0:
archived_messages_percent = round((archived_messages / total_messages) * 100, 2)
unarchived_messages_percent = round(
((total_messages - archived_messages) / total_messages) * 100, 2
)
else:
archived_messages_percent = 0
unarchived_messages_percent = 0
# Define start_year and current_year here
current_year = datetime.now().year
start_year = current_year - 4
# Admin Message Delete - Bar Chart By Year ... Archived and Non-Archived
messages_per_year = (
Message.objects.filter(
timestamp__year__gte=start_year, timestamp__year__lte=current_year
)
.annotate(year=ExtractYear("timestamp"))
.values("year")
.annotate(
archived_count=Count(
Case(When(archived=True, then=1), output_field=IntegerField())
),
unarchived_count=Count(
Case(When(archived=False, then=1), output_field=IntegerField())
),
)
.order_by("year")
)
years = list(range(start_year, current_year + 1))
archived_counts = [0] * 5
unarchived_counts = [0] * 5
for item in messages_per_year:
index = years.index(item["year"])
archived_counts[index] = item["archived_count"]
unarchived_counts[index] = item["unarchived_count"]
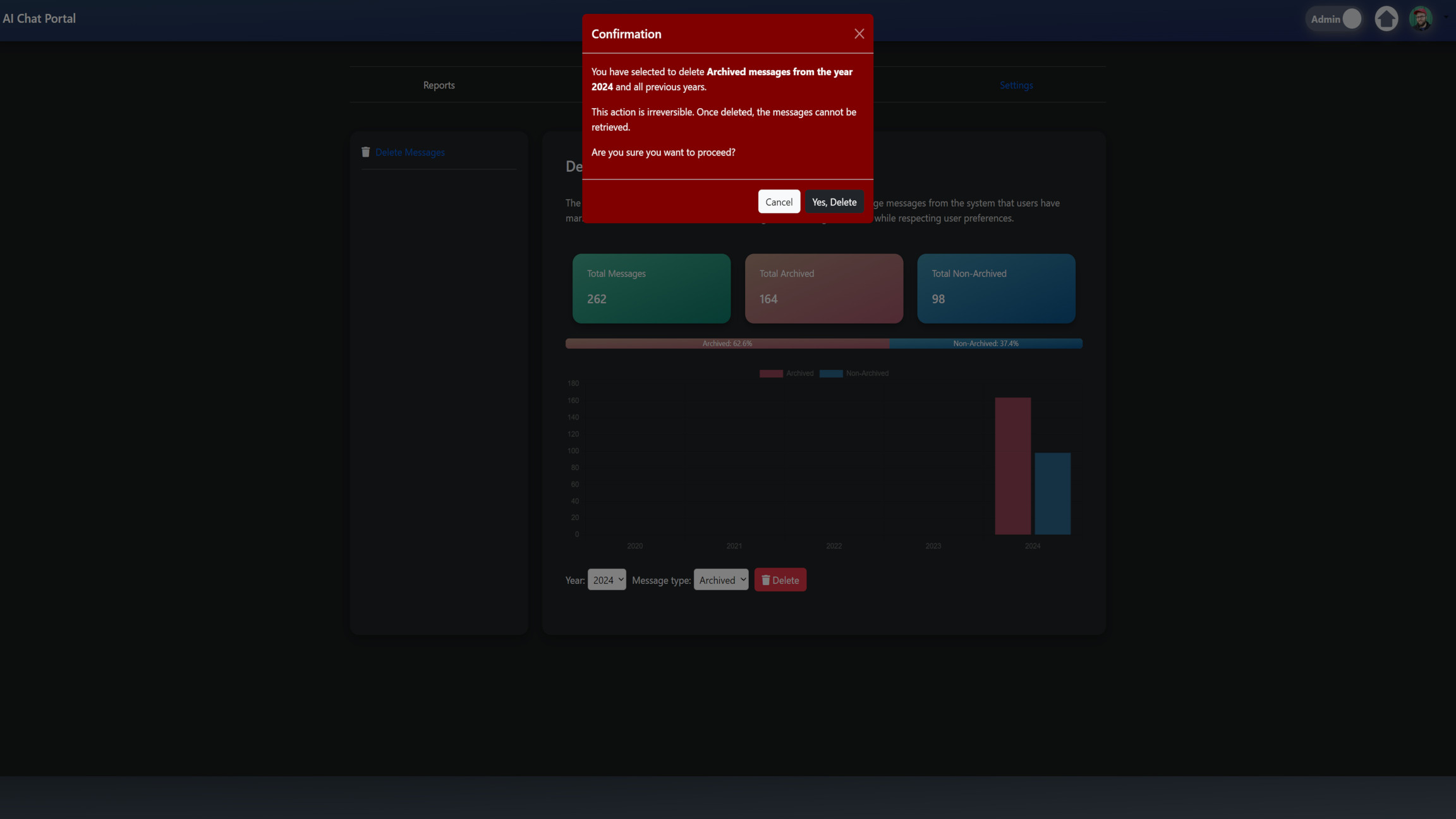
if request.method == "POST":
form = DeleteMessagesForm(request.POST)
if form.is_valid():
year = int(form.cleaned_data["year"])
message_type = form.cleaned_data["message_type"]
# Build the deletion criteria for messages from the specified year and all previous years
criteria = {
"timestamp__year__lte": year,
}
if message_type == "archived":
criteria["archived"] = True
# Delete based on the criteria
Message.objects.filter(**criteria).delete()
# Redirect or render as needed
return redirect(
"aichat:admin_home_settings"
) # Redirect to the same view or another view as needed
else:
form = DeleteMessagesForm()
context = {
"form": form,
"total_messages": total_messages,
"archived_messages": archived_messages,
"unarchived_messages": unarchived_messages,
"archived_messages_percent": archived_messages_percent,
"unarchived_messages_percent": unarchived_messages_percent,
"years": years,
"archived_counts": archived_counts,
"unarchived_counts": unarchived_counts,
}
return render(request, "admin/aichat_admin_settings.html", context)
Here’s a breakdown of how this function works:
-
Message Statistics: The function starts by calculating the total number of messages, as well as the counts and percentages of archived and unarchived messages. This helps in providing an overview of the message storage.
-
Year Range: It determines the range of years (current year and the past four years) for which it will generate statistics and deletion options.
-
Messages Per Year: It calculates the number of archived and unarchived messages for each year within the defined range, storing the results in lists for display.
-
Delete Messages Form: When the form is submitted via POST request, the function processes the form data to determine the year and type of messages to delete. It constructs criteria based on this information and deletes the matching messages.
-
Rendering the Template: Finally, it prepares the context with all the necessary data, including message statistics, year ranges, and the form, and renders the template for the admin settings page.
This feature is crucial for maintaining the system’s performance and managing storage by allowing administrators to delete old or unnecessary messages efficiently. It provides a clear and interactive interface for managing message data, helping keep the system organized and responsive.
Tests
Testing is a crucial part of my development process to ensure that the application functions correctly and meets the specified requirements. Here are some of the tests I wrote to validate various aspects of the application's functionality.
AI Chat Tests
In the TestAIChat class, I created several tests to verify the behavior of the chat functionality with various user settings and conditions.
class TestAIChat(TestCase):
def setUp(self):
self.user = CustomUser.objects.create(username="TestUser")
self.ai_model = AIModel.objects.create(
name="gpt-3.5-turbo",
api_key="redacted",
)
def test_no_user_settings(self):
response = chat_with_gpt(self.user, "hello")
self.assertEqual(
response, "Error: User Does Not Have Associated AI Chat Settings."
)
def test_rate_limits(self):
settings = AIChatUserSetting.objects.create(
user_ID=self.user,
model_ID=self.ai_model,
requests_per_rate=2,
rate_duration=AIChatUserSetting.HOUR,
)
# First message, should pass
response1 = chat_with_gpt(self.user, "hello")
self.assertNotEqual(
response1,
f"Error: You've Hit Your Limit Of {settings.requests_per_rate} Messages Per {settings.rate_duration} Please Wait.",
)
# Second message, should pass
response2 = chat_with_gpt(self.user, "hello again")
self.assertNotEqual(
response2,
f"Error: You've Hit Your Limit Of {settings.requests_per_rate} Messages Per {settings.rate_duration} Please Wait.",
)
# Third message, should fail
response3 = chat_with_gpt(self.user, "hello once more")
self.assertEqual(
response3,
f"Error: You've Hit Your Limit Of {settings.requests_per_rate} Messages Per {settings.rate_duration} Please Wait.",
)
def test_rate_duration(self):
settings = AIChatUserSetting.objects.create(
user_ID=self.user,
model_ID=self.ai_model,
requests_per_rate=1,
rate_duration=AIChatUserSetting.HOUR,
)
# Create the object first
message = Message.objects.create(
user=self.user, model=self.ai_model, message="Old Message"
)
# Update the timestamp and save again
message.timestamp = timezone.now() - timedelta(hours=2)
message.save()
# Should pass because the old message was sent 2 hours ago
response = chat_with_gpt(self.user, "hello")
self.assertNotEqual(
response,
f"Error: You've Hit Your Limit Of {settings.requests_per_rate} Messages Per {settings.rate_duration} Please Wait.",
)
def test_request_token_maximum(self):
settings = AIChatUserSetting.objects.create(
user_ID=self.user, model_ID=self.ai_model, request_token_maximum=5
)
long_message = "hello " * 1000 # Very long message
# Should fail due to length
response = chat_with_gpt(self.user, long_message)
self.assertEqual(
response,
"Error: Please Shorten Your Message Length. You've Hit Your Message Length Limit.",
)
- test_no_user_settings: Verifies that the system returns an appropriate error when a user does not have associated AI chat settings.
- test_rate_limits: Checks that the system enforces message rate limits correctly.
- test_rate_duration: Ensures that the rate limits reset after the specified duration.
- test_request_token_maximum: Confirms that messages exceeding the token maximum are correctly identified and rejected.
Ajax Chat Tests
In the AjaxChatTests class, I created tests to validate the behavior of the AJAX chat endpoint with valid and invalid inputs.
class AjaxChatTests(TestCase):
def setUp(self):
self.client = Client()
self.user = get_user_model().objects.create_user(
username="testuser",
password="testpassword",
)
AIChatUserSetting.objects.create(user_ID=self.user, enabled=True)
def test_ajax_chat_valid_input(self):
self.client.login(username="testuser", password="testpassword")
url = reverse("aichat:ajax_chat")
response = self.client.post(url, {"textareafield": "hello"})
self.assertEqual(response.status_code, 200)
self.assertIn("ai_response", response.json())
def test_ajax_chat_invalid_input(self):
self.client.login(username="testuser", password="testpassword")
url = reverse("aichat:ajax_chat")
response = self.client.post(url, {})
self.assertEqual(response.status_code, 200)
self.assertIn("ai_response", response.json())
self.assertIn(
"<p>Error: Please provide valid input for me to help you with.</p>",
response.json()["ai_response"],
)
- test_ajax_chat_valid_input: Verifies that a valid input to the AJAX chat endpoint returns a successful response containing an AI response.
- test_ajax_chat_invalid_input: Ensures that an invalid input to the AJAX chat endpoint returns an appropriate error message.
These tests help ensure the reliability and correctness of the application's features, enabling the ability to catch issues early and maintain high-quality code.
Sources:
- Chat GPT API - OpenAI API Documentation
- spaCy Large Language Model
- AJAX Introduction - W3 Schools
- Font Awesome
- Bootstrap Documentation
- How To Chat - W3 Schools
- Python Markdown Library
- Python Bleach Library
- Web Application Framework - Django
- Django for Beginners: Build websites with Python and Django
- Django for Professionals: Production websites with Python & Django
- Django for APIs: Build web APIs with Python and Django